Creating a suitable file uploader for web apps
As you can imagine, this time, we are not using the radio button. Instead, we are directly uploading the files. So, referring to Figure 12.7, let’s comment all the code between lines 11 and 31.
Immediately in the subheading, on line 10, we can add file_uploader, this time including all three types:
raw_text_file = st.file_uploader(‘Upload File’, type=[‘txt’, ‘docx’, ‘pdf’])
When we try to upload the file from the browser, this time in our directory, we will see all three types of files and be able to select one of them.
As we did on line 15 in the code presented in Figure 12.5, we can check that the file is not null by writing the following:
if raw_text_file is not None:
After this if clause, we must get the details of the file. We need these details to understand which type of file we selected and how to manage it. By using the raw_file_text variable, which contains the file we uploaded, we can use three methods named name, type, and size to collect the details we need.
These details will be put into a dictionary; we are calling it file_details. Let’s see it in the code:
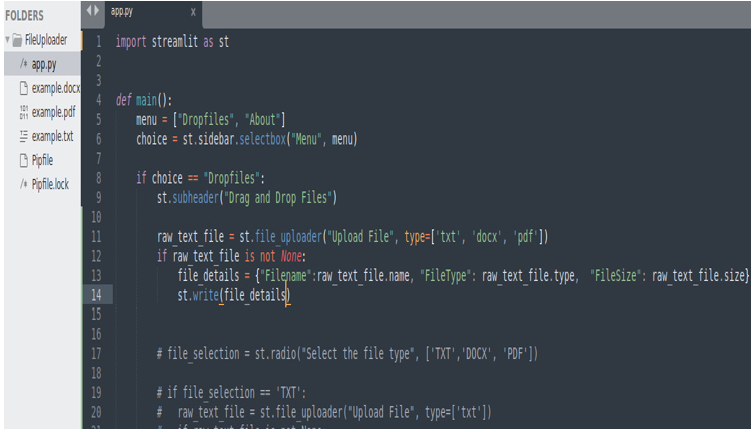
Figure 12.8: The code for file upload and file detail detection
This is the result in the browser:
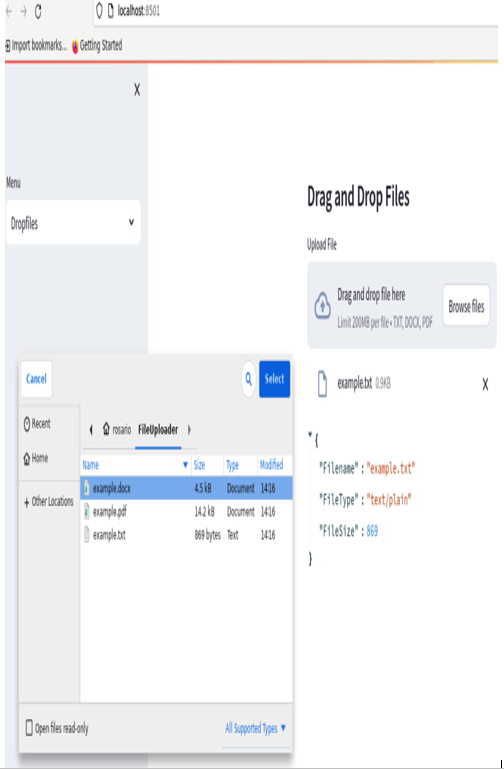
Figure 12.9: File upload and file detail detection in the browser
As we can see, in the directory, we have all three types of files and can select any one of them since the information about the file details has been intercepted correctly. In the case of the .txt file, we got the correct filename, the text/plain type, and its size.
Let’s see what type we get for the .docx and .pdf files. The .docx file, as shown here, has a very long type file:
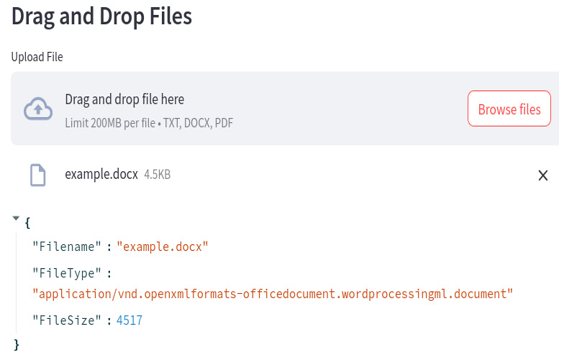
Figure 12.10: The .docx file
Meanwhile, the .pdf file has a shorter name:
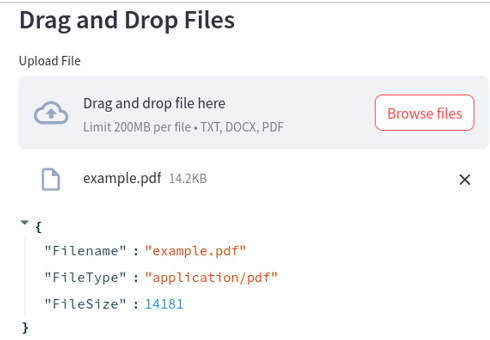
Figure 12.11: The .pdf file
These three different types of files are all we need to manage file uploading automatically. To open the .pdf and .docx files, we need to install the proper libraries (pdfplumber and docx2txt). So, please write the following command in your terminal:
pipenv install pdfplumber docx2txt
The first package takes care of .pdf files, while the second takes care of .docx files.
Once the installation is finished, we must import these libraries into our app.py file by typing the following:
import docx2txt
import pdfplumber
With that, we have everything we need. So, referring to Figure 12.8, continuing from line 15 of our code, we can write the following:
if raw_text_file.type == “text/plain”:
try:
raw_text = str(raw_text_file.read(), “utf-8”)
st.info(“Text from TXT file”)
except:
st.write(“TXT File Fetching Problem…”)
The preceding code checks that the type of file we uploaded is text/plain. In this case, it reads it, stores its content in a variable named raw_text, and prints a label on the screen saying just Text from TXT file. This check happens in a try cycle; so, in case of an error, a simple exception will be printed on the screen.
The same code we used for the .txt file has to be used for the other kind of files; the only differences are the type of the files and the libraries needed to read the content of the files (the two libraries we just imported – that is, pdfplumber and docx2txt).
Let’s look at the code shown in Figure 12.12:
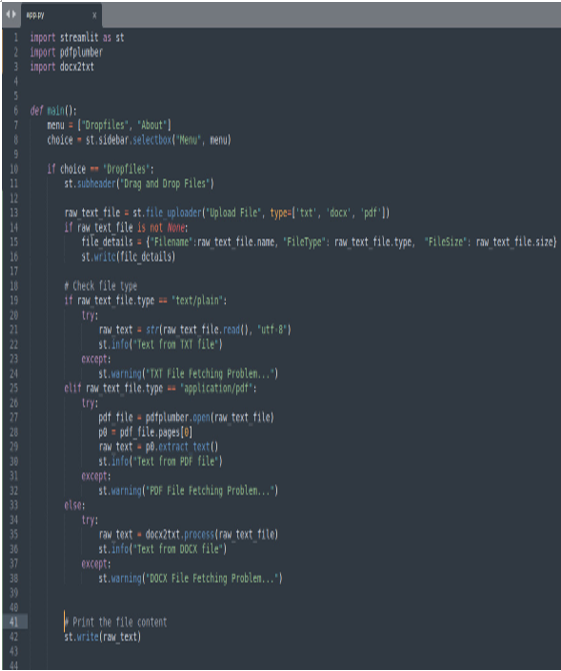
Figure 12.12: The code that automatically uploads the files
On line 27, we used pdfplumber because the file type is “application/pdf”, while on line 35, we used docx2txt because the file to open is a .docx file.
Finally, on line 42, we automatically print the contents of the opened file on the screen.
This is the result in the case of a .docx file; please note the very long name of the file type:
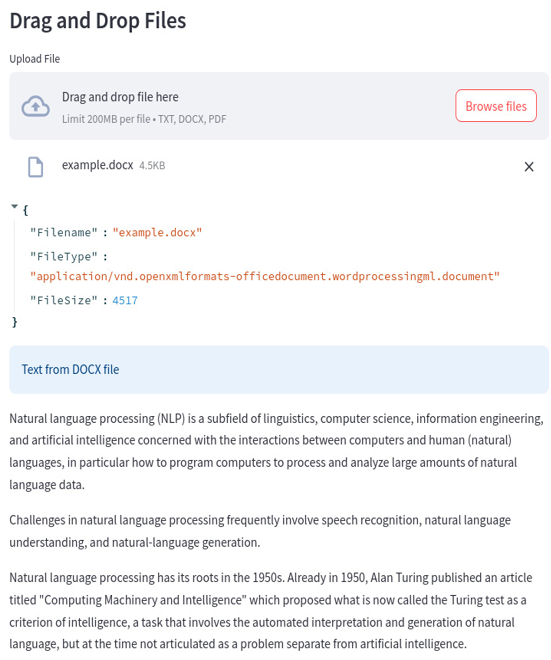
Figure 12.13: A .docx file is automatically recognized and opened
The application behavior with a .pdf file is the same:
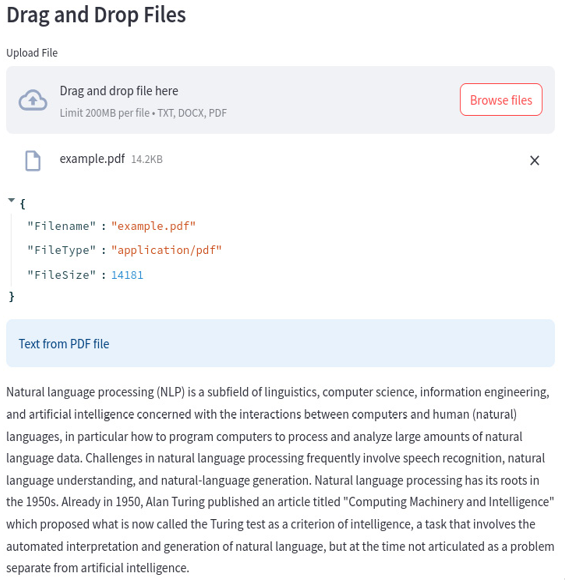
Figure 12.14: A .pdf file is automatically recognized and opened
So far, we have learned two ways of uploading files: asking the user about the file type and making the file uploading process automated. Both approaches are valid, and which one you should choose depends on the use case. Simplifying our web apps with smart components should always be the preferred solution.


